Introduction
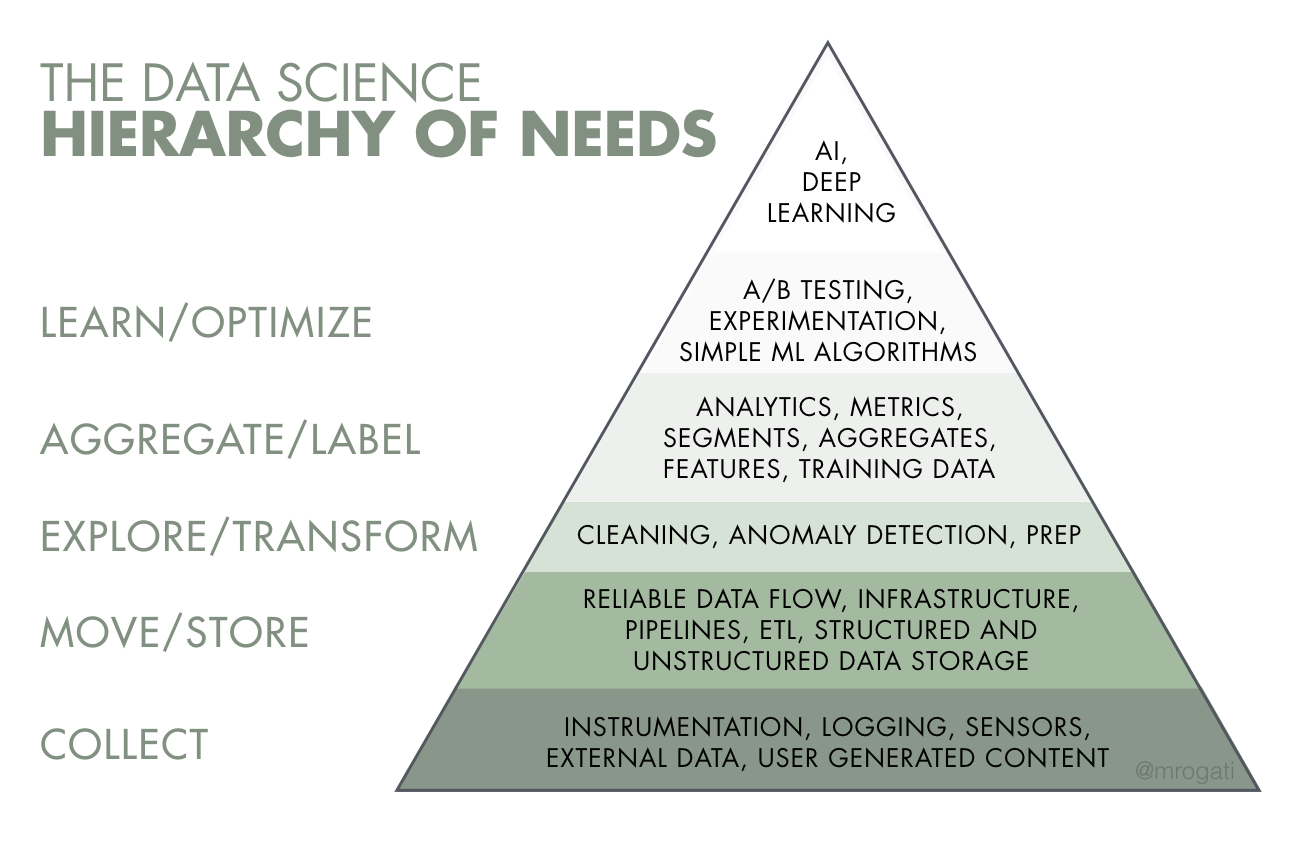
At Mozilla, we're quickly climbing up our Data Science Hierarchy of Needs 1. I think the next big step for our data team is to make experimentation feel natural. There are a few components to this (e.g. training or culture) but improving the tooling is going to be important. Today, running an experiment is possible but it's not easy.
{kind=link}
I want to spend a significant part of 2018 on this goal, so you'll probably see a bunch of posts on experimentation soon.
This article is meant to be an overview of a few principles I'd like to be reflected in our experimentation tools. I stopped myself from writing more so I could get the article out. Send me a ping or an email if you're interested in more detail and I'll bump the priority.
Decision Metrics
An experiment is a tool to make decisions easier.
Sometimes, this isn't the way it works though. It's easy to let data confuse the situation. One way to avoid confusion is maintaining a curated set of decision metrics. These metrics will not be the only data you review, but they will give a high level understanding of how the experiment impacts the product.
Curating decision metrics:
- limits the number of metrics you need to review
- reduces false positives and increases experimental power
- provides impact measures that are consistent between experiments
- clarifies what's important to leadership
I plan on explanding this section into its own post.
Interpretability
We should value interpretability in our decision metrics. This sounds obvious, but it's surprisingly hard to do.
When reviewing our results, we should always consider practical significance. Patrick Riley explains this beautifully in Practical advice for analysis of large, complex data sets :
With a large volume of data, it can be tempting to focus solely on statistical significance or to hone in on the details of every bit of data. But you need to ask yourself, “Even if it is true that value X is 0.1% more than value Y, does it matter?”
...
On the flip side, you sometimes have a small volume of data. Many changes will not look statistically significant but that is different than claiming it is “neutral”. You must ask yourself “How likely is it that there is still a practically significant change”?
One of the major problems with p-values is that they do not report practical significance. Also note that practical significance is difficult to assess if our decision metrics are uninterpretable.
More on this coming soon.
Decision Reports
Experiment results should be easy to export to plain text. This allows us to capture a snapshot from the experiment. Data doesn't always age well, so it's important to record what we were looking at when we made a decision. This will make it easier for us to overturn a decision if the data changes.
For the foreseeable future, experiment results will need review to be actionable. Accordingly, we should include our interpretation with the experiment results. This is another advantage of exporting results in plain text; Plain text is easy to annotate.
There will always be context not captured by the experiment. It's important that we capture all of the reasoning behind a decision in one place. The final result of an experiment should be a Decision Report. The Decision Report should be immutable, though we may want to be able to append notes. Decision reports may summarize more than one experiment.
1 Source: https://hackernoon.com/the-ai-hierarchy-of-needs-18f111fcc007